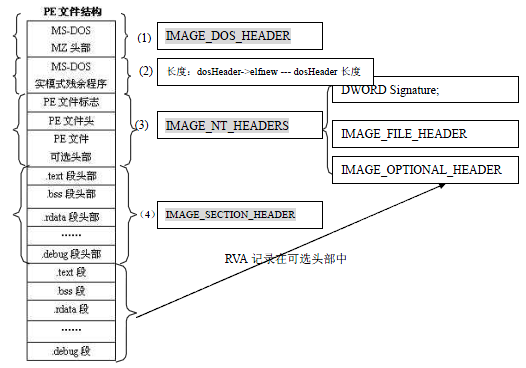
上一篇主要是很初略的总结了是什么,这篇要总结下为什么。以下部分参照了http://msdn.microsoft.com/en-us/magazine/cc301727.aspx和http://blog.donews.com/zwell/archive/2005/10/21/596302.aspx两位大牛的文章。和上述不同的是本文主要的涉及内容来自win7。当然我这里并没有真正的涉及win7,以及Vista所加入的新内容,(因为那些对现在的我来说实在是太复杂了)。win7 只是一个壳子,我描述的核心是在win2K,甚至是在windows3.1这些版本中就已经有的。当然为了能够更详细的理解整个过程。反汇编了部分loader的源代码。 pseudocode下载。
当然,我看到的windows loader的代码对我来说依然是非常庞大,这里仅仅记录了程序正确路线,并没有完善错误路线,往往是return error来结束。当然,在代码中,难免有错误,特别是对我来说,这是第一次从汇编角度观察windows。也希望各位大牛,能够帮我指出里面的错误。
一开始本来是想长篇大论的去写这一篇文章,因为涉及到的内容实在太多。而且大部分都是再重复大师们的内容。这里实在是不敢造次。仅仅记录一些自己认为有必要重复和自己所遇到的问题。上面2篇文章非常值得研究,如果你也对这方面感兴趣。
最后,由于最近时间很紧,代码还是缺少了一些部分。还有相当一部分需要去完善细节,现在之所以记录,仅仅害怕时间长了。自己会懒惰而没有记下这个过程。当然,我会在这个《PE文件初探系列》的最后补全代码。
当我们调用LoadLibraryEx LoadLibrary类似的函数,我们会进入到LdrpLoadDll,就让我们从它开始载入过程。
LdrpLoadDll的大体思路Russ Osterlund,已经解释的很清楚了。为了查阅方便,原谅我这里只是简单翻译重复一下。
检查这个module是否已经被载入过了 将没有载入的module映射到地址空间 遍历module的导入表,找到是否需要再导入其他的module。需要则导入并递归1。 所有相关的module载入完毕后,更新module load count。 初始化module 清理一些结尾工作。更新module Flag。 首先我们遇到的一个重要的函数是LdrApplyFileNameRedirection。这个函数主要是为了解决Dll hell。一种Side-by-Side Assembly的技术,相关的信息可以参考。http://dipplum.com/2009/11/09/side-by-side-assembly/。SxS已经大大超过了我所能解释的范围。原谅我先跳过这步。在STATUS_SXS_KEY_NOT_FOUND后,我们来到了一个非常重要的函数LdrpFindOrMapDll 。
遍历进程LdrpHashTable,查找dll是否已经载入 查找是否是系统已知KnownDll。 查找dll文件名,并修正到完整路径名。 遍历peb中的InLoadOrderModuleList查找dll是否已经载入 没有找到则将dll映射到地址空间 这个函数还是比较简单的。但是我却遇到了一个让我很费解的问题。
_KSYSTEM_TIME
+0x000 LowPart : Uint4B
+0x004 High1Time : Int4B
+0x008 High2Time : Int4B
#define MM_SHARED_USER_DATA_VA 0x7FFE0000
#define USER_SHARED_DATA ((KUSER_SHARED_DATA * const)MM_SHARED_USER_DATA_VA)
KUSER_SHARED_DATA ksd;
eax=ksd.SystemTime.High1Time;
ecx=ksd.SystemTime;
edx=ksd.SystemTime.High2Time;
KSYSTEM_TIME ktime;
//real code
//eax=[0x7ffe0018];
//ecx=[0x7ffe0014];
//edx=[0x7ffe001c];
do
{
ktime.High1Time= ().High1Time;
ktime.LowPart=().LowPart;
ktime.High2Time= ().High2Time;
}
while(ktime.High1Time!=ktime.High2Time);
//code end
typedef struct _KUSER_SHARED_DATA {
/* Current low 32-bit of tick count and tick count multiplier.
* N.B. The tick count is updated each time the clock ticks.
*/
volatile ULONG TickCountLow;
UINT32 TickCountMultiplier;
/* Current 64-bit interrupt time in 100ns units. */
volatile KSYSTEM_TIME InterruptTime;
/* Current 64-bit system time in 100ns units. */
volatile KSYSTEM_TIME SystemTime;
/* Current 64-bit time zone bias. */
volatile KSYSTEM_TIME TimeZoneBias;
} KUSER_SHARED_DATA, *PKUSER_SHARED_DATA;
以上结构是wrk上的代码,win7的比他复杂太多了,而且其他的数据成员我们也并不关心。
这是在LdrpFindOrMapDll最后,把数据插入到InLoadOrderModuleList,InMemoryOrderModuleList中遇到的。
这个其实是获得系统时间的过程。更为详细的地方在这里http://www.dcl.hpi.uni-potsdam.de/research/WRK/2007/08/getting-os-information-the-kuser_shared_data-structure/
简单的说。当clock ISR 处理的时候是先更新High2Time,然后LowPart,High1Time。 而用户程序读取的时候是反着的顺序。 而这一切都是为了同步。但构成这个成立的前提是volatile 关键字,也就是说这样虽然减少了lock的时间,但是却也放弃了CPU的缓冲机制,每次都写操作都必须通过内存。而这个时间更新的速度是如此之快(100ns?),那么是不是同样会对效率造成冲击呢?相信MS一定做了不少测试来衡量利弊,但是再面对现在的多CPU下。是否一定适合呢?这里面涉及到太多有关硬件的知识,缓存的算法。CPU调度等等。。。这个问题还是交给10年,甚至20年后的我吧。这里标记下。更希望大牛能给出解释。//TODO:
如果我们的dll被载入了(原来没有,刚刚被映射),那么我们通常会遇到LdrpProcessStaticImports ,而LdrpCorProcessImports,我这里似乎没有遇到。//TODO这里需要完善。
BasepProbeForDllManifest ,原谅我再次跳过一个函数依然和dll hell有关,这些高级的东东,还是等我们弄清楚基本的东西回过来再解决他们。
LdrpProcessStaticImports
修改相应页面为PAGE_READWRITE。 如果dll 绑定 则采用绑定方式载入dll 如果没有dll 绑定或绑定失败则已普通方式载入dll 恢复相应页面。 先看普通方式载入。我们来到了LdrpHandleOldFormatImportDescriptors。这里我们遍历导入表,对每个导入表的module调用LdrpHandleOneOldFormatImportDescriptor。
LdrpLoadImportModule 将相应的module导入 调用LdrpProcessStaticImports。查找ped的ldr的StaticLink。找到则更新load count。没有找到则初始化并插入链表首部。 更新IAT表。 LdrpLoadImportModule 这是一个非常重要的函数。
LdrpApplyFileNameRedirection。
LdrpFindOrMapDll
LdrpProcessStaticImports
LdrpHandleTlsData //这里相关dll初始化的部分,会在下一篇文章中总结。目前,我们只是关心载入。
完毕后插入InInitializationOrderModuleLis 这里就有点麻烦了。这里面涉及到了很多的递归。让我们重新理解下。
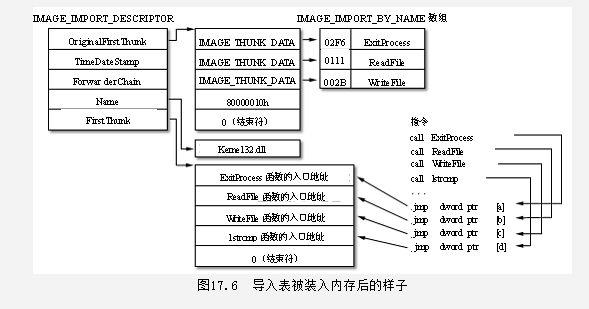
当我们程序编译链接成可执行程序后。loader会检查我们程序,通常可是.exe的文件。操作系统发现有一些dll文件需要载入(我们程序中使用了dll的函数,最通常的例子就是我们使用的系统API,那些函数的代码并不在我们.exe里,而在系统dll中,如ntdll,gdi32.dll等,所以我们必须把他们载入CPU才能执行代码),那么我们需要首先从dll导入表中查找我们需要的dll。去寻找那些我们调用的函数。就和上一篇文章中提到的MessageBox函数。但是,我们发现我们的MessageBox函数地址并不是真正函数的地址,loader 需要遍历dll的导出表。而在那里,我们找到了函数的地址,然后经过计算,loader帮我们把函数真实地址添入。而这个真实添入的地址所构成的表则为IAT表。MS的编译器还会保存另一个表,是在IAT添入之前的样子,叫做INT表。而其他的编译器可能并没有这个表生成。比如Borland。为什么保留这个INT表,等绑定之后再解释。
OK,看样子十分完美,我们找到了我们所需要的dll的地址,但是事实上却很复杂。因为我们所导入的dll,很可能使用了另外的dll的代码中的函数。那么我们必须递归的调用,来把我们.exe中所有有关系的dll,都载入才能保证我们执行时,IAT表中的代码地址,真实的是我们需要的代码。有了这个大体的感觉。让我们查看整个过程的细节。
LdrpSnapIAT
LdrpSnapIAT做的事情也很简单,遍历导入表内容,并查找导出表内容,再调用LdrpSnapThunk。
LdrpSnapThunk
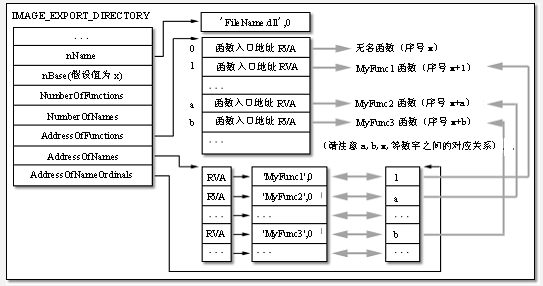
遍历导入表,根据序号或名字查找导入函数。 遍历导出表,查找相应导入函数的地址。 将计算好的函数地址添入IAT表。 函数很好理解,当我们使用函数名字查找时,会遇到一个很重要的函数LdrpNameToOrdinal,Russ Osterlund的precode给出了详细代码,我觉得win7在这里并没有太大改动。LdrpNameToOrdinal是一个简单的二分法在导出表中查找匹配函数位置。而如果我们使用序号来查找,则可以直接定位到函数地址,而不需要经过这么一个字符串查找过程。当然不管是按照名字还是序号查找之前,有一个编译器给我们的提示,hint来查找函数。(不过这个真的没什么用。面对那么多的导出函数,就提示一个。怎么可能满足要求?)。
不管用什么方法,我们总算是朝着我们的目标前进了。但是另一个问题来了。有些函数的地址却在导出表中,这就是dll函数的转发问题。
什么是转发?
我们之前说我们需要查找一个函数的地址,我们找到了这个xxx.dll。但是这个xxx.dll却告诉我们,这个函数地址也不在他那里,而在xxxx.dll里。这个就是转发的过程。用那个破的再不能破的例子就是kernel32 的HeapAlloc 转发到了ntdll中。
那么为什么要有转发?
看样子,似乎是MS在给我们打马虎眼,通过转发来保证他的源代码不被泄露。给我们一个表面的公开函数,然后去调用它不公开的函数。除了这一点,转发函数的另一个重要的特点是,他割断了部分dll之间的关系。
让我们首先回头看一下,会发现,loader在做这个添入IAT表的时候是十分辛苦的。
即便是使用了二分法来查找。但是面对字符串的挨个比较。这个效率是无法接受的。如果有些dll导出了上百了dll。还有一些长长的名字(事实上会更长,因为如果用c++,编译器还要加名字)。 IAT处在代码段,是可读的。会在多个进程之间共享。一个进程对共享数据页面做了修改,操作系统会启动copy_on_write机制去创建另一个页面然后把修改的数据保存下来。为这个修改页面后的进程保留一个private的页面。如果我们的dll在多个进程载入的地址相同。那么我们就会有一大堆的private页面,但是却完全一样。这确实浪费了我们的资源,操作系统分配页面的时候,可不会去比较页面是否一样。(//TODO:check windows也许会在某些时间真的去比较这些页面是否相同,然后相同会修改成共享,但是由于我英文太差,不知道老外是瞎扯还是真有,时间也很长了,页面也一时找不到了。。。无奈)。 当然我们一般的应用程序,不会有那么多的函数去做,但是MS自己却是地地道道的需要做。面对那么多的API函数。MS提供了一系列的优化载入dll的措施,分别节省了link时间(转发),重定位时间(rebase),添入IAT表时间(bind),延迟了载入时间(delay load)。同样也适用于我们的应用程序。(不过效率有多大的提高呢?反正肯定是有的)。当然,每一个解决都不是完美的方案,都有自己的缺陷。
我们首先遇到了转发。
转发的直白意思是,这个函数我提供一个入口,但是实现的代码却在别的dll中。那么他是如何提高我们的dll载入效率呢?
如果我们在程序中调用了A.dll,A.dll 使用了func1 ,func2,func3。而func1被转发到了B.dll中的Bfunc1。如果我们在A.dll中使用了func1那么,我们必须载入B.dll。但是如果我们在A.dll中,没有使用func1,那么如果func1是转发到B.dll的,那么我们就不会载入B.dll,而如果我们是通过导入的方式做func1,那么不管是否使用,我们都要载入B.dll。为什么?因为我们的.exe和A.dll建立的关系,而A.dll的导入表中有B.dll,A和B的这种紧密关系,使我们不得不把B.dll载入进来,但我们的.exe却永远不会使用B.dll中的任何函数。(如果我们不使用A.dll中的func1)。而转发,则可以避免这个情况。因为在A.dll的导入表中,没有Bfunc1。
OK,转发函数。割断了部分DLL之间的联系。他直接减少了link的时间。这个好。彻底不用载入了。
让我们继续LdrpSnapThunk。的转发处理
查找是否是转发函数,在export table中。 比较是否是ntdll(不管是大写还是小写还是都有,反正都算)。相等则直接获得ntdll的 forwardEntry。//TODO:这里总觉得有种很怪的感觉,很怪很怪的感觉。 如果不是ntdll,那么我们回到了原点调用LdrpLoadDll。 (可选)调用LdrpRecordForwarder,查找ldr的ForwarderLinks。没有则添加。并更新load count。 最后调用LdrGetProcedureAddressEx,获得相应函数地址。 由于LdrGetProcedureAddressEx涉及到了dll的初始化问题。所以这篇不细说,下一篇再总结他。
转发给我们解决了一个问题。那些不使用的没关系的dll,并没有被我们载入进来。但是如果我们使用了函数,依然会有IAT表的添入,查找,那一系列的问题。OK。让我们来看看另一个解决方案。绑定。不过在这个之前,需要理解下重定位。
重定位部分的代码,Russ Osterlund没有写,我也没有写(希望后面我能完善了)。有关的知识网上很多。这里不重复了。只是解释下原因。我们在程序中的绝大部分数据都是相对的偏移量。因为我们不能确定我们的PE文件最终会被操作系统载入到那个位置上去。在编译和链接的过程,我们是相对一个默认的位置来生成相应的代码。这些默认值,会被写到PE头文件中去。windows loader在载入的时候,如果发现有冲突,则会重新计算这些偏移量。当然,为了减少这个运算。我们可以通过rebase来处理。
还是让我们把注意力集中在bind上面。
我们看到loader首先就是查找是不是可以使用bind来做。
LdrpHandleNewFormatImportDescriptors
遍历绑定描述符表,和导入描述符表。查找是否匹配 成功则调用LdrpHandleOneNewFormatImportDescriptor,否则返回INVALID_IMAGE_FORMAT(0xC000007B),直到0。 LdrpHandleOneNewFormatImportDescriptor
LdrpLoadImportModule,加载module LdrpRecordStaticImport 加载导入的一系列东东 如果bind失败,则调用LdrpSnapIAT。 如果bind成功,则遍历绑定转发表。IMAGE_BOUND_FORWARDER_REF,依次调用LdrpLoadImportModule, LdrpRecordStaticImport。 最后不管bind是否成功调用LdrpFixupIATForRelocatedImport。 //TODO LdrpFixupIATForRelocatedImport,没有全部完成,真不知道MS搞一个这个巨大的函数名字有什么深意。看来是逼我把这个重定位做了,: ) 。
bind这部分比较难。LdrpFixupIATForRelocatedImport的部分我没有完成,所以这部分应该是有很多值得推敲的地方。
等最近不忙了。再彻底搞定他。
最后剩下了一部分。就是INT的问题。这个问题的出现是为了我们在处理bind失败所必须的。当bind被失败后,我们不得不和原来一样去做。这是INT表作用体现处理了。当然如果没有INT表。整个载入则会直接down掉。
使用bind,我们将避免了动态添入IAT所需要花费的空间和时间。这的确是一个是非优秀的设计。但是同样的。他的条件实在太苛刻了。如果其中有部分更新的操作系统,某个系统的dll被更新了。那么这一切也随之破灭了。他实在是太脆弱了。
最后写给自己的
这的确不是一篇完整的文章。因为有太多太多的知识对我来说是一个空白。每一个函数后面都可能是给我打开一个新的世界。在没有对已经存在的世界有一个清醒的认识前,非常容易造成溢出。有时候,真想找一个事情,可以就像操作系统分配物理内存一样。你什么时候使用给你一点,而且还能具有不错的缓存性能。而在这整个过程最郁闷的就是要不什么也没有,要不多的你放不下。而且各种跳转,冲击着我可怜的缓存。。。如果把我比作一个运作的很困难的操作系统。那么这篇文章就是我其中的一个页文件再适合不过了。
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
哎,也许我的实力太差了。这篇的姊妹篇,初探一已经被博客园从首页上抹去了。这篇也可能和上一篇同样的命运。我可能要创一个记录了,虽然不是那么光彩,10篇文章2篇都被毙掉。如果加上这一篇,就是第三篇了。哈哈。我只知道Matt Pietrek 在2002年的MSJ上写道。
“You might be wondering why you should care about the executable file format. The answer is the same now as it was then: an operating system’s executable format and data structures reveal quite a bit about the underlying operating system. By understanding what’s in your EXEs and DLLs, you’ll find that you’ve become a better programmer all around.”。
当然,我不该提Matt Pietrek,因为我把“我”和他的名字放到一起就是其实就是对他的一种不尊敬。我也不敢扯我懂PE。我甚至只能皮毛都不了解。因为涉及到太多有关操纵系统、编译器、连接器的细节。对于我这个菜鸟来说也的确没有这个资本谈论这个问题。我也不想说别的。只是想发泄下自己的情绪。仅此而已。