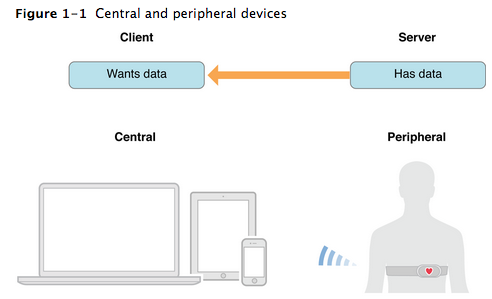
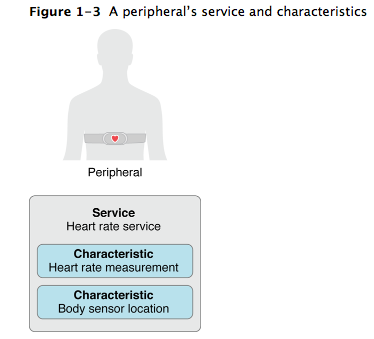
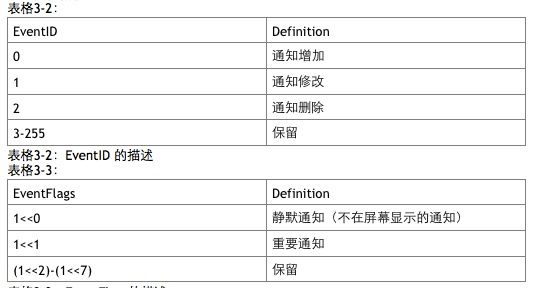
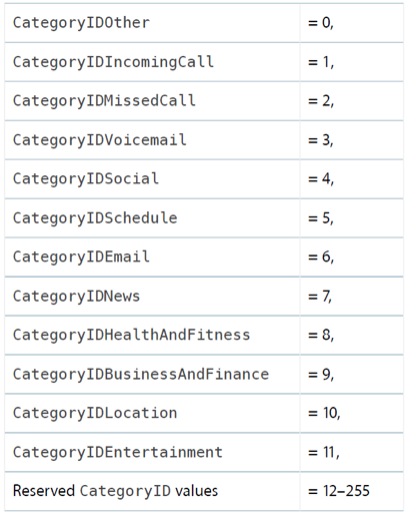
最近看了一些有关server的东西,一些很简单的东西,不外乎是一些文档规范,另外结合最近看的wwdc的一些video,觉得对软件架构(software architecture)认识又清楚了一些,这里记录下来。
software architecture 听上去是一个很大的概念,实际上也包括很多东西,里面的争议也很多。在我看来软件架构最好放在小的场景中理解。
问题1
我们有2个页面。

demo code 1.0.0
2个页面分别显示一个数字,这个数字应该相同。详情会修改这个数字,这里我们发现,详情页面和主页面数字不一样。
 数据不一致
数据不一致
问题1 解决方法A
这里首先的感觉就是,详情页面返回,主页面数据没有刷新,导致数据不一致。
那么Fix这个Bug的方法,就是在主页面出现的时候刷新界面
- (void)viewWillAppear:(BOOL)animated {
[super viewWillAppear:animated];
self.displayLabel.text = [[CUDataDAO selectData].data stringValue];
}
现在来看,还不错。但是,我们调用selectData的次数则变得非常非常多。数据不是经常变化的。
demo code 1.0.1
问题1 解决方法B
我们发现既然数据的改变是在页面B进行的,那么页面B修改这个数据的时候,应该把数据变化”通知”给页面A,那么我们写了一个Delegate
@protocol CUDetailViewControllerDelegate <NSObject>
- (void)detailVC:(CUDetailViewController *)vc dataChanged:(NSNumber *)data;
@end
在页面B修改数据之后,通过delegate 通知给页面A。
- (IBAction)changeButtonClicked:(id)sender {
int value = arc4random() % 100;
[CUDataDAO setData:value];
self.displayLabel.text = [@(value) stringValue];
if ([self.delegate respondsToSelector:@selector(detailVC:dataChanged:)]) {
[self.delegate detailVC:self dataChanged:@(value)];
}
}
到此场景1得到了不错的解决。
demo code 1.0.2
问题2
这时我们增加了另一个页面C。这个场景会稍微抽象一点,我们定义了3个数据
- 页面A的数据dataA
- 页面B的数据dataB
- 页面C的数据dataC
问题1中 dataA = dataB。在问题2中dataA = dataB + dataC;
问题2 解决方法C
也就是说页面C的修改,也会影响页面A的数据,那么我们是不是也要写一个XXXXDelegate呢?
这时我们的大脑嗅出了一些不好的味道,如果再来个什么dataD,dataE,我们要写这么多的Delegate么?对于多对一”通知”这种味道,很自然的想到了不用Delegate,而是用NSNotification来做。让我们未雨绸缪一下,定义一个Notificaiton
NSString *const kCUDataChangedNotification = @"CUDataChangedNotification";
[[NSNotificationCenter defaultCenter] postNotificationName:kCUDataChangedNotification
object:nil
userInfo:nil];
那这个变化broadcast到listener,看上去是一个很赞的idea。
demo code 1.0.3
问题3
过了一段时间,我们发现问题2的方法有一个Bug,当界面停在页面B的时候,切换到页面C,修改数据,B中再返回时,数据和页面A的数据不一致。
 数据不一致
数据不一致
那也可以类比解决方法B,得到了下面的方法
解决方法D
既然A和B的数据不一致,而A的数据比B的新,那么保留一个B的指针,然后A变化的时候,更新B就好了。
- (void)handleDataChangedNotification {
[self updateLabel];
[self.vc updateLabel];
}
// In a storyboard-based application, you will often want to do a little preparation before navigation
- (void)prepareForSegue:(UIStoryboardSegue *)segue sender:(id)sender
{
if ([segue.identifier isEqualToString:@"push"]) {
CUDetailViewController *vc = [segue destinationViewController];
if ([vc isKindOfClass:[CUDetailViewController class]]) {
self.vc = vc;
}
}
}
demo code 1.0.4
问题4
页面C实在是太简单了,这次我们希望在页面C中显示页面A的数据。因为上次我们就产生了一个数据不一致的问题,这次我们注意到了,那么怎么修改呢?
解决方法E
在看了看整个APP各种通知之后,觉得挺麻烦,准备用一个取巧的方法。可以类比解决方法A。在页面C出现的时候,刷新数据,至于什么性能问题,不管了,先fix bug。
- (void)viewWillAppear:(BOOL)animated {
[self updateLabel];
}
- (void)updateLabel {
int dataB = [[CUDataDAO selectData].data intValue];
int dataC = [[CUDataDAO selectOtherData].data intValue];
self.dataLabel.text = [@(dataB + dataC) stringValue];
}
demo code 1.0.5
问题5
这时的数据需要不断的变化,我们在CUDataDAO加了一个timer 模拟数据变化,数据变化的原因可能是server push 一些数据。client 本地数据库更新了数据,需要在页面A、B、C中显示。
页面C的数据又不一致了。。。。
问题到底在哪里呢
走到这里,我们需要重新思考为什么这个问题会不断的重复出现呢?software architecture就是来解决这个问题的。但是在提出一个合理的方案之前,先思考一个概念。
我们把数据库中的数据,显示到屏幕上,或是传递给View时,这个过程其实是对data 做了一次copy。而且只要不是通过引用或是指针这些方式,通过值传递的方式都是对data做了一次copy。而这个copy的过程,非常类似Cache。

通常建立一个Cache会遇到2种问题。
- Cache情况A: 与original Data 数据不一致,没有及时更新
- Cache情况B: 重复建立Cache
让我们用这个思路来看我们的解决方案
解决方法A
这是一个非常典型的Cache情况B。数据库的数据并没有变化,但我们却多次重复计算cache
解决方法B
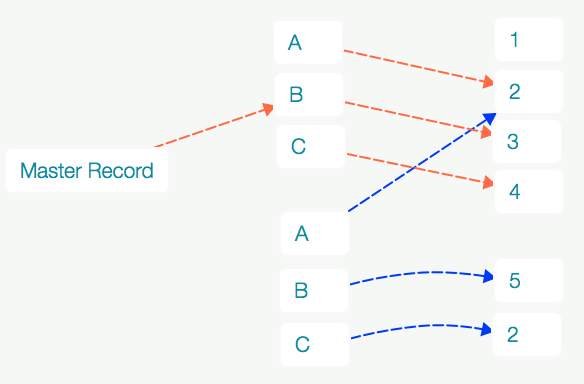
页面之间的关系可以用下面来描述

这里我们隐隐能够感觉到问题,A的数据变化依赖于2个地方。不急,再往后看
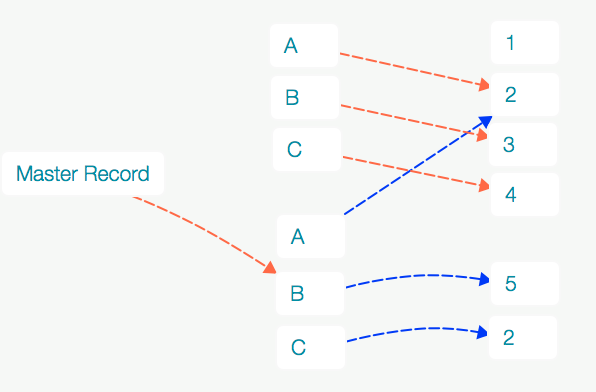
解决方法C

解决方法D

事情变得更糟了
解决方法E
和解决方法A类似,同样的重复计算Cache问题。
实际上问题还会更糟
现在还是一个简单的Model,如果project变得很大,那么就会变成这个样子

每一个X都可能是一个Bug。
我们似乎已经找到问题了
《Advanced iOS Application Architecture and Patterns》 中,把这个图叫做information flow。我们的直觉会告诉我们,这个信息的传递,应该是自上而下的树或是森林,而且最好是一个层次平衡结构,要清晰,每一个位置都有相对于的职责。那我们就需要制定一个规则。
在想这个规则之前,如果把上面的图背后的数据忘记,我们感觉这很类似内存模型。当然内存模型会比较复杂。但是我们可以借鉴很多”内存管理中的规则”,比如谁创建,谁销毁。同样,在我们的information flow中,我们希望谁创建Cache,谁更新Cache变化
DAO的数据库似乎很难做这件事情,我们引入了一个新的元素dataSource(当然他本身又是DAO的一个Cache)。其中A、B、C3个都会显示数据,那么他们应该在一个层级,其中B、C会修改数据,他们会把这个数据返回给dataSource,而通过dataSource来把这个变化通知到A、B、C。

这样带来的好处很明显,我们再添加一个D,也不会对其他地方的数据产生任何影响,我们的Unit Test、Mock也更加好写。
我们之前的思路错在哪里呢?
从局部来看,我们之前的思路都没有任何问题,但是整体来看却把问题隐藏化。关键的问题是在于没有找到Truth,找到问题真正的地方。而找到真正的地方,需要我们在大脑中有一个清晰的information flow或是data flow。了解之间元素的相互关系,才能建立一个个的层。才能坐到真正的解耦,解耦并不是仅仅一个个的Manager,更重要的是建立一套清晰的flow机制,或是消息机制,如果没有一套flow,中间引入的各种各样的方法,即便使用了各种设计模式,整个software 依然是深度耦合。
疑问
这个APP看上去交互非常复杂
上面的model,有些同学还可能觉得这是交互上面的问题,这个交互看上去非常的复杂,不是一个好设计。
我这里列举一个实际的例子:
A页面要创建动画,动画背后包括很多数据,这些数据会在B,C甚至更多的页面,或是后台被修改。动画本身实际上体现在View,而这些view可能不仅仅在A中有,B,C可能也会有部分的View。
单例怎么样
当然我们可以用单例的法子。单例是个魔鬼,被很多滥用,这个场景用单例,其实仅仅是把全局变量合理的封装在了单例下,因为这份数据,并没有任何理由要一定是一份copy。
recap
在了解这个概念后,再看一些server的架构,规则时,也会更容易理解这些层之间的关系。包括
- 为什么要规定那些层之间,不能相互调用,不能有静态方法。
- 一个层之间的model,不能有重叠功能,不能连表查询。
- 在哪个层才能调用另一个服务,而调用这个服务还必须要通过统一的接口
software architecture 涵盖的东西非常多。这篇只是一个引子,介绍了设计之前的准备工作。但是在实际过程中,我们的模型可能要比我这里写的还要复杂很多。下一篇会介绍一种策略用来处理更加复杂模型的情况。
最后附上一个完整功能的 demo code
参考
《Advanced iOS Application Architecture and Patterns》
]]>



















")
")