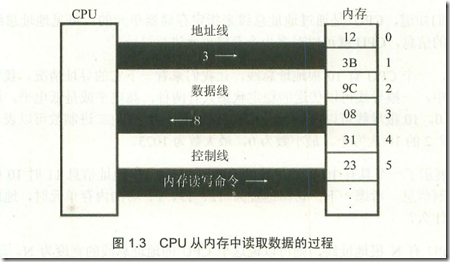
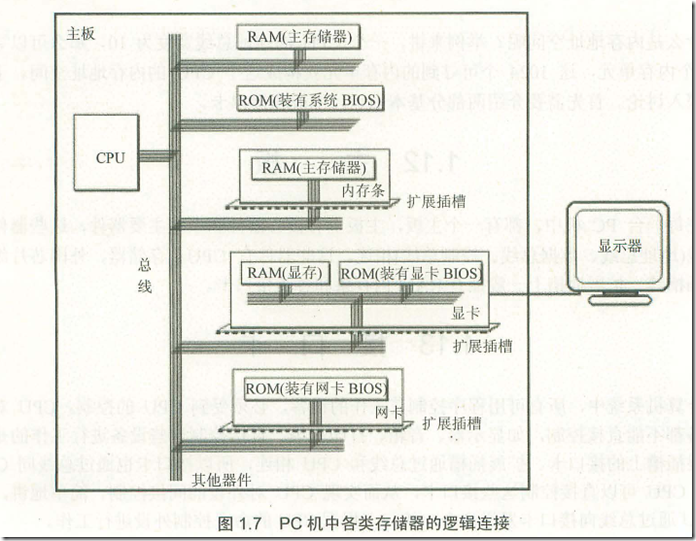
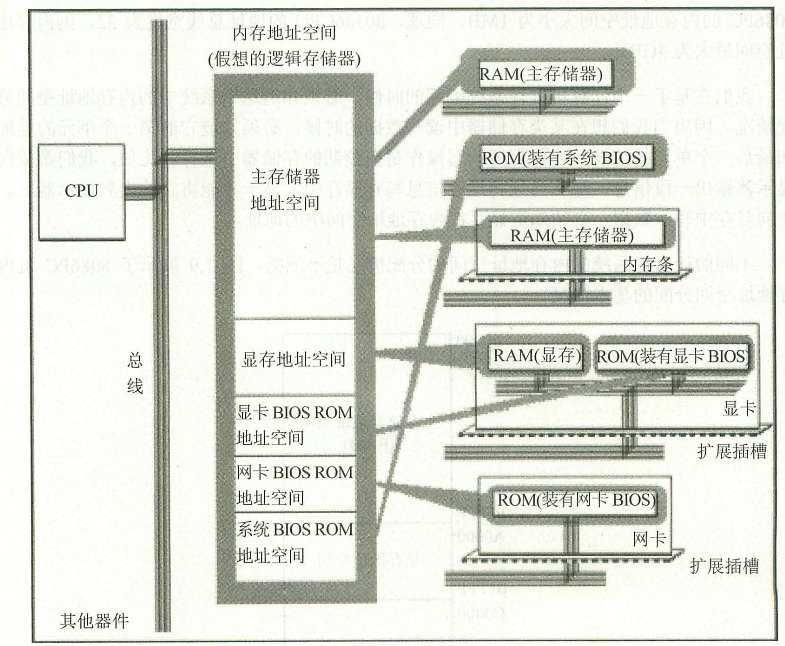
不得不说,有时候无知是福,看到一点有趣而深刻的东东,就能感觉到神奇。越是我们熟悉的东西,往往却是我们进一步理解深刻的障碍,而之所以是障碍是我们并不知道这个是我们理解问题的障碍。困惑中的每一次豁然开朗往往是从一点一滴的我们已经成为惯性思维中开始。越是深刻的原理,往往越是简单强大。就像爱因斯坦打破牛顿给我们原有的世界观一样。对于一个打破常规,让你重新理解问题的最简单的方法就是把你整个思考的前提否定。而带来的结果就是我们看问题的角度,层面有了更大的扩展。所以,有时候知道的太多反而不美,做一个白痴也很幸福。
哎,又无病呻吟了半天。之所以有上述感想。还得感谢自己的同学。由于我没有看过MIT的经典课程《算法导论》而被鄙视,而且更无语的是,我的理由是“听不懂,如果有老师的课堂发音的记录”,而事实上。这个MIT早就提供了,为了照顾想我这样的听力不好的家伙。好吧,我是个白痴,不过就像上面讲的,白痴也有白痴的幸福。这个假期,无聊的时候,不仅可以看《爱情公寓2》也可以屡屡自己的数学常识了。:)
《算法导论》是一名研究算法设计的课程。设计算法,我们关心的主要是2个方面,一个是性能,另一个是资源花费。当然,我们重点的是性能,我们总是希望我们的程序跑的更快。那么学习算法到底有什么用呢?这是一个经典的问题。Charles Leiserson 是这样给我们解答的。首先,列举了一大堆在实际编程中比性能更重要的东西:可维护性,模块化,功能,用户体验等等。特别是用户体验,那么既然有这么多的东东比算法重要,那么为什么我们还要学习算法呢?
算法决定了可行还是不可行。
在一些实时的情况下,比如机器人等嵌入式设备,我们不够快,那么就没有意义,如果我们用了太多的内存,同样不行。所以,算法这个东东,总是在我们计算机领域的最前沿部分,如人工智能,搜索引擎,数据挖掘。如果我们是在做10年前就已经实现了的东西,那么性能的确在一些情况下已经不重要了。但是,如果想做一些别人没有做过的东西,真正的实现从无到有的过程。那么其中遇到的绝大多数问题都是,数据太复杂了。没有能力在有限的资源下找到答案。这也就是为什么叫计算机科学,而不是计算机工程。(当然科学这个和名字是无关的,比如物理,从来没有那个学校叫个什么物理科学什么的。:))。不得不说,MIT的目标是为世界培养leader,而我们那破学校是为了培养farmer(这里并没有不敬在里面,而且事实上,做一个farmer挺好的,每年坐在家里,收个房租,年末村里再分个几十万,比那些城里白领好多了在物质上)。其实也不那么绝对,非要改变世界,只要是之前没有做过的程序,我们在实现之前,首先思考的一定是算法。其次,则是对他不断的优化,完善。
对绝大多数的刚刚参加工作的同学,往往不能体会到整个产品的创建过程。参与的仅仅是完善,算法的设计或是大体设计已经完成,所以感觉不到算法的存在。而匆匆下了学校白学的定论。而随着工作时间变长,总会遇到没有或是不能直接利用原有设计的东东,那么算法也就体现出价值了。
算法是一种描述程序行为的通用语言。
我们可以通过算法去描述程序的运行流程,在任何地方。他不仅能在实践中得到体现,也能在理论中得到证明。而且能够得到大家一致的看法。而这是别的永远无法做到的,比如用户体验,每个人都有自己的想法,我们不可能让所有人都满意我们的设计,而算法却可以做到,因为快就是快。放到计算机上一跑结果自知。别人无法击败你,即便是再挑剔的对手,只要你足够出色。而能够满足这样条件的前提就是,算法是一个如此一般化,基础的东西。就像Charles Leiserson 所讲,算法就像钱,你可以用钱去买吃的,喝的。而衡量这些花费的就是钱的数目。在计算机上,则是,选择一个这样的策略,需要花费多少。选择另一个策略,需要花费多少。而衡量这2个选择谁的花费多呢?是算法。
算法在计算机中的地位,就和数学在所有理科学科中的地位一样。我曾经问过我的数学老师一个问题,他的回答让我直到现在还记忆犹新。“老师,数学在您眼中是什么呢?”“数学是所有理科中是最奇妙的一个。因为他可以独立于其他任何学科存在而其他学科离开不了数学。”是的。能够想象物理化学离开数学之后是什么样子么?但是数学为什么能够独立存在?是因为他构建了一门语言,一门伟大的语言。使用这门语言可以让知识在任何领域中环绕,学好数学就好像有了一张无限透支的通用支票,可以在任何地方花费(黄金?)。作为一个可以让这么多地方都通用的原因中最重要的就是,他是超级稳定的。是一个说一不二的世界。一个公平的世界,绝对的世界(当然,现在数学这个概念也不准确了,这个充分体现了哲学思想,有正必有反啊:P)。他所确定的东西的结果是肯定的。没有歧义,而且不随时间变化而流动。比如,我们真实世界中交流的语言,比如“忽悠”,“猥琐”。等等。很多词义,随着时间的变化而改变了。使得很多年纪大的人,和我们这年轻人在交流上就产生了隔阂。而我们最熟悉另一个例子就是文言文,特别是其中的一些扭曲的字。但数学这种基础类学科是不会的。至少在一个可以预见的范围是稳定的,没有地域限制的。所以,数学才能站在人类科学发展的最前沿,他的每一次前进的一小步,都能改变世界。这就是数学之美。同样也是自己能够让绝大多数人接受的最大障碍。由于他改变的太慢,而且枯燥。绝大多数人无法深入的理解。当用世俗,腐烂,充满铜臭,功利的眼光看待纯净的数学世界,必然发现数学无用。而且,这的确是事实,因为大部分人,都不可能成为改变世界的家伙(这里的确不准确,因为改变世界话题太大,修理地球同样也是改变世界。)。
算法,同样为我们计算机构建了一个纯净的世界。一个说一不二的世界,他所确定的,没有能够反驳的。当然,就和学习数学一样,我们不是去成为数学家,学习物理,不是去成为物理学家,然后去做哪些能够改变世界的东西。学习这些基础类学科的重要在于,他提供了一个让我们和那些站在人类史上最顶尖的家伙们交流的语言,从我的角度来看。如果没学好数学,能够和牛顿,爱因斯坦交流么?没有学好算法,能够和高爷爷交流么?作为一个普通人,我们只要学习到他们身上的一点点,也就足够了。当然,这不是对所有家伙都有效,有些人总是想,和那些老家伙有什么好交流的,给我一个周杰伦的签名吧。:)
学习算法还有一个原因,是的,就是兴趣。这个传说中最牛X的老师。
喜欢算法,没有别的原因,是的。我就是喜欢比别人快速的感觉。喜欢数学,是的。因为大部分人数学不好。所以我就喜欢数学。迎难而上,哥就是喜欢做别人做不了的东西。是的,虽然听上去很牵强,而且比较扭曲。比较符合印象中90后的想法。不知道90后是不是能产生更多的数学家呢?
让我们回到我们的算法上,既然我们这么关注性能,那么什么是影响性能的因素呢?
对于一个计算机外行来说,首先就是计算机硬件本身的运算能力。多一个超级牛的CPU,超大的内存,固态硬盘。肯定运算快。的确,如果你拿一个超级计算机和地摊上买的一个小的计算器比运算能力。这个实在是一个很显然的结果。是的,所以,我们有些情况下,需要思考在相同条件下,到底哪个算法的性能更高。这比较的是相对速度。但是我们却不能忘了这一点。有时,我们想使用一些很一般的计算机,通过优秀的算法,来打败那些拥有更高硬件的那些家伙们,而我们则必须关心算法性能的绝对速度。那么我们该如何描述这些看似互相矛盾的东西呢?不要忘记,算法可是基础啊,我们要的是一个确切的答案。我们如何给出一个确切的答案,而这个答案不管是超级计算机,还是普通PC都能够支持呢?这就是算法中最重要的一个概念,甚至是一切分析的大前提,一个可以把这些复杂的因素都考虑在内(或是都不考虑在内)的东东转换为可以用数学分析的对象。这就是渐进分析。
渐进分析的基本思想是
忽略硬件结构
不使用真实世界的运行时间,而是关心运行时间的增长速度为对象
渐进分析是一个非常庞大的概念,我们最熟悉的,也是大多数本科院校教我们的就是Θ,O,Ω等等类似的这些符号。这里只从Θ开始。
对一个初学者,Θ-notation是比较容易接受的。对一个多项式,我们只需要删除掉所有的低次幂项,忽略掉常数,系数这些次要因素。就和Charles Leiserson 所讲的。这个描述,是工程方向的描述,并不是严格的数学上的定义。而对像我这样的小白来说,最大的误解就是把他当成了数学上的严格定义而产生了极大的困惑。
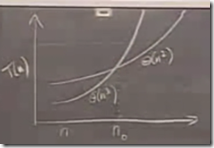
这个是一个相当经典的图,当n趋于无穷大时,Θ(n3)总能干掉Θ(n2)。不管是同样的硬件设备,还是不同的硬件设备。只是在不同的设备下,不同的算法下,我们有了一个不同的系数,低次幂项,和常数。但是,我们关心的是他随着数据输入长度的变大而产生的增速。当n超过n0时,任何的次要因素都是浮云了。我们就可以说Θ(n3)被Θ(n2)干掉了,即使Θ(n3)的硬件要比Θ(n2)好很多,在一开始的时候效率有多高。
这是一个伟大,cool的概念。是的,他完美的既满足了我们追求的绝对速度,也能满足我们追求的相对速度。可以说,这给了我们继续学习算法的动力。但是,事实上,在实际开发中,我们有时候却使用那些在学校中认为是效率低的算法。难道这个理论错了?当然不是,错的是我们,我们忽略了一个很大的前提,n0。在我们多数开发过程中,很少接触那些海量数据的运算。我们的运算多数是在一个较少的数据上下浮动,这个也可以说我们的硬件,资金,产品,根本不需要我们整那么大的数据。也就是n0,我们根本达不到。事实上,只要是有脑子的,看到这个图,在小于n0的前提下,都会做成正确的判断。但对于刚刚步入IT的广大学生,却总是犯下屁股决定脑袋这样愚蠢的选择。而这其实,就是做科学和做工程师的最大区别。理论和实践相互掰手腕的结果。
这几天,挖老赵的“坟”,找出了这么一篇。写程序时该追求什么,什么是次要的?里面有一段十分搞笑的代码,之所以这样说,是因为我自己也写过这样的代码。想想真是dt啊。回想事发现场,我记得是我看了个什么类似《面试宝典》东东,有一些题考察交换元素,事实上,你可以找到一大堆的,而且是更精妙的去交换2个元素。看到之后,如获至宝。只要是2个元素要换位置,就用。站在做科学的角度上看,这无可厚非。但是如果站在工程的角度来看。这就是明显的画蛇添足。往往花费80%的精力在提高%20的性能上,而不是去花费20%的精力提高80%的性能。这同样是刚刚步入IT的广大同学的问题。做科学需要严谨,但是在工程方面,考虑的事情非常复杂,多。我们必须要关注在核心,关键的部分。这样才能在有限的资源下,最大的做出东东来。实践中,没有任何项目的资源是足够的。MS,Google都会有资源不足的时候。我们需要学会抓住重点。当然这里并没有鄙视这些面试问题,事实上,这些问题的背后往往是考察数学思维的基本功,而不是鼓励大家这么做。就像那个经典的问题,12个小球一架天平。没有仔细,严谨的思考,能够想到这个东东能和排序问题扯上勾么?神啊,万恶的功利,给完美的数学模型批了一层邪恶的外套,使我们在追求本质的过程中迷失。
有关n0的问题,不仅在算法设计上,也出现在我们的设计模式之中。《设计模式》这本神书,我是没看过,也不敢看。但也隐隐感觉到类似“设计过度”的言论。这同样都是在理论和实践结合上出了问题。当然,不少理论支持者,肯定会说,那是因为你没做过那么大的项目。但事实却是,不管设计多么复杂的,还是多么简单的,实践和理论永远不可能都得到满足。windows操作系统可以说是一个我们可见的最大的项目之一了。但是windows也并不是一个微内核,在内核中也绑定了非常多的“多余”的部分从理论上看。那无疑会降低系统稳定性,提高维护难度。但是我们却不能不说windows是最成功的一套软件之一(这个之一甚至都可以去掉)。
当然,要想在做学问和实践找到平衡点。这个无疑是极大的挑战。只是分析理论,而不实践,那么永远不可能成为一个出色的工程师。除非你的目标是成为理论科学家。反过来,如果不理论而只是实践,不同的是,这个是可以成为一个出色的工程师。所以,这里有一句经典的话。
If you want to be a good programmer, you just program ever day for two years, you will be an excellent programmer. If you want to be a world-class programmer, you can program every day for ten years, or you can program every day for two years and take an algorithms class.
既然算法是如此的重要,那么我们该如何学呢?其实,这是一个很纠结的问题。甚至是一个鸡生蛋,蛋生鸡的问题。不学算法,你不会了解他,也不会认识到算法重要,反而。认为算法不重要,那么也就不会下功夫去学。这就又回到一开始的那个unknown unknown上了。所以,如果准备学习算法,也就意味着选择了一条坎坷的路。一开始特别迷茫,但是没有别的选择。唯有坚持,放下浮躁,功利的心态,沉浸在数学的世界中才能体会到数学的价值,数学的乐趣。也只有这样,才能坚持到最后。
当然,能做到这一点的,敢说体会到数学之美的家伙,全世界也没有几个人。那么作为一个普通人,我们怎么才能最大的去提高自己,更好的掌握实践和科学的平衡点呢?这个问题,我自己也没有答案。因为我既没经验又没理论。这里只是扯下我自己的理解,可能很偏激。
首先应该研究下刘未鹏的很多博客内容,特别是锤子和钉子。对我这样的新手来说,武器真的太少了。所以当捡到一个武器往往过于兴奋而忽视了这个武器的使用前提,往往杀鸡用牛刀,而且还达不到积极的效果。就是因为我们拿到锤子之后,所有东西看上去都像钉子。所以,我们唯有摆正心态,深入了解拥有的武器,并增加更多的武器,见更多的市面,才能坐怀不乱,达到手中有锤,心中无锤的最终境界。
一个稍微实际的例子。对像我这样的菜鸟来讲,大部分都会遇到这样一个问题。而且困惑很久很久。“堆排序为什么比快速排序在大多数时要慢呢?”事实上,造成这个问题的主要原因(对我)就是,没有理解明白Θ-notation。那些被忽略掉的次要因素,当然还有更重要的是数学上对概率的薄弱理解。然后我们会再映射出一大堆的数学基础知识,然后大部分人死在沙滩上(真的,这是我从小以来最大的遗憾,就是没有学好概率,而造成这个的原因居然是,这些题目初学时往往是用日常用语出题,而由于本人语文太差,总不能理解清楚题意,而对这类题目产生了极大的抵触,可见小朋友们千万不要偏科:P)。从科学的角度去,完全可以证明这个问题,但是付出的代价就是没有硕士以上的数学能力的玩家,没有机会理解到那个层次。那么,其实我们可以从另一个角度看,直接放到计算机上跑一下就可以了么。是的,我不是科学家,我只需要知道结果就OK了。是啊,好在我们处在一个和谐的世界。让我们从这个庞然大物中得以解脱,所以,有时,我们需要根据自身情况,放弃一些东西,特别是那些比较能够通过实验来证明的东西。
好吧,总不能啥也放弃吧,都放弃了那到底也简单了。这里,我只能说,我推荐SGI STL。在我看来,这是一个结合了设计模式,理论算法与实践最好的一个实例。他不仅是开源的,代码量也不多,命名也算规范,而且还有一本侯捷大师的著作来诠释,帮助我们理解,而且还能帮助我们具体实践过程中规避一些错误。我们每一个在学校学习的算法,我们都可以在这里找到答案(至少可以用来做作业拿高分对某些特别的女生),而且都会比一般大学讲的深刻,事实上,我认为,大学现在的教育为什么觉得无用,不是太难太理论,而是教的太简单了,简单到已经没有用的地步了,从而根本没有实际意义。(大学联合培训机构,是我所见过的,比大学扩招还要搞笑的事情)比如快速排序,SGI STL做了非常多的优化来保证无论在什么时候,都不会退化到n2,在分的过程总是分不好时,采用堆排序。在快速排序到做最后几步,为了减少开销而采用插入排序去做哪些马上就要排好序的部分。而这些策略,并不是凭空想象,都可以在高爷爷的著作中找到理论证明,以及网上的各种论文,前提是你的数学功底足够(当然这里实践在前还是理论在前这个实在是没有讨论的意义)。所以,理论不是没有用,只是自己学的太肤浅。实践也不是没有用,只是自己没有考虑那么多的情况,想的太简单而已。
当然,这个可能又会引起另一个庞大的问题,“不要重复制作轮子”,不过这个已经大大超出这篇文章的范围了。我自己的看法是,STL是为了实现最基本的最通用的东东的,而实际过程中,我们往往有自己的特殊性。而这些特殊性是STL不可能设计时都给我们考虑周全的。也就是我们很可能需要扩展,重写部分以适合我们的需要。当然,现在离这些目标还很远很远很远。