在应用程序中,常常需要将一个集合U(键值集合)和另一个集合T(数据集合)建立关系构造dictionary结构,来达到增删查改的需求。如果键值集合很小,那么可以直接采用Direct-address tables的方式实现。
假如我们的集合 U = {0, 1, …, m - 1}, 而且m并不大。如果我们的键和值对应唯一,那么我们可以通过构造一个大的数组来保存集合U,如下结构。
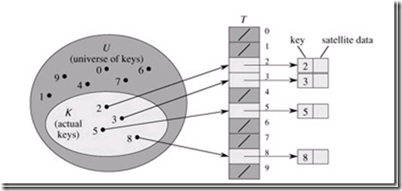
显然,当集合U增大,那么直接存储集合U变的不那么明智起来,而且,如果使用键的集合K变小是,我们浪费的空间也越来越大。当集合K比集合U小很多的时候,就是hash粉墨登场的时候了。hash将保存空间压缩到集合K的大小,并且控制查找元素的时间仍在O(1) 在平均情况下。
hash 通过hash函数h,将集合U 映射到hash表T[0,…, m-1]中, 即 h : U → {0, 1, …, m - 1}。显然,由于集合大小的限制,很可能造成有相同的key 指向了hash表中的同一项,如图。
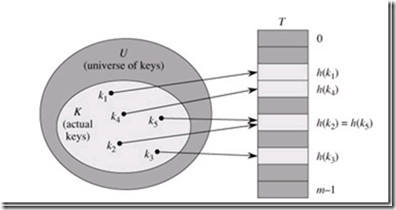
我们将这一情况称为碰撞(Collision),解决碰撞的方法很多,最容易想到的是通过链表来保存碰撞的key。
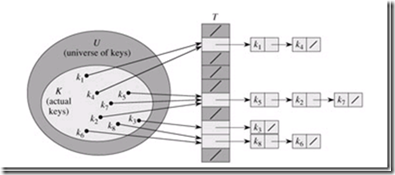
一个简单的例子,linux2.4 在处理进程中,需要一个通过pid找到进程的要求,而具体实现则是利用了hash。在处理冲突时,采用的是链表的方法。不过由于是操作系统的代码,所以这里并不是通常意义的双向链表,pidhash_next 指向后一个进程,但是pidhash_pprev指向的是前一个进程的pidhash_next的地址。虽然不长,但是理解这段还是需要稍微动下脑筋,系统之所以这么实现,似乎是能够提高增加和删除时链表的效率。
/* PID hashing. (shouldnt this be dynamic?) */
#define PIDHASH_SZ (4096 >> 2)
extern struct task_struct *pidhash[PIDHASH_SZ];
#define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1))
static inline void hash_pid(struct task_struct *p)
{
struct task_struct **htable = &pidhash[pid_hashfn(p->pid)];
if((p->pidhash_next = *htable) != NULL)//如果发生的冲突
(*htable)->pidhash_pprev = &p->pidhash_next;//这里可以看出,pprev是上一个进程的next指针的地址
*htable = p;
p->pidhash_pprev = htable;//新的进程的pprev是指向了hash表项中的自己的地址
}
static inline void unhash_pid(struct task_struct *p)
{
if(p->pidhash_next)//如果有冲突
p->pidhash_next->pidhash_pprev = p->pidhash_pprev;
*p->pidhash_pprev = p->pidhash_next;//当没有冲突时,就会置NULL
}
static inline struct task_struct *find_task_by_pid(int pid)
{
struct task_struct *p, **htable = &pidhash[pid_hashfn(pid)];
for(p = *htable; p && p->pid != pid; p = p->pidhash_next);
return p;
}
SGI STL的例子 hash
SGI STL中的hashtable 同样采用的是开链法设计,这里就是hashtable中节点的样子
template <class _Val>
struct _Hashtable_node
{
_Hashtable_node* _M_next;
_Val _M_val;
};
这里可以看出,hashtable并没有利用现有的list等容器,而是自己简单的创建一个单向链表并维护。由于hashtable中的每一项元素都是一连串的数据(处理冲突而在一个链表中),所以将hashtable中的元素成为bucket,表示这个元素其实可能有“一桶子”东西,最后hashtable通过vector管理bucket,实现动态增长。
同之前一样,首先从iterator开始了解。下面是hashtable的iterator实现。
template <class _Val, class _Key, class _HashFcn,
class _ExtractKey, class _EqualKey, class _Alloc>
struct _Hashtable_iterator {
typedef hashtable<_Val,_Key,_HashFcn,_ExtractKey,_EqualKey,_Alloc>
_Hashtable;
typedef _Hashtable_iterator<_Val, _Key, _HashFcn,
_ExtractKey, _EqualKey, _Alloc>
iterator;
typedef _Hashtable_const_iterator<_Val, _Key, _HashFcn,
_ExtractKey, _EqualKey, _Alloc>
const_iterator;
typedef _Hashtable_node<_Val> _Node;
typedef forward_iterator_tag iterator_category;
typedef _Val value_type;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef _Val& reference;
typedef _Val* pointer;
_Node* _M_cur; //指向当前的节点
_Hashtable* _M_ht; //指向hashtable容器
_Hashtable_iterator(_Node* __n, _Hashtable* __tab)
: _M_cur(__n), _M_ht(__tab) {}
_Hashtable_iterator() {}
reference operator*() const { return _M_cur->_M_val; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& __it) const
{ return _M_cur == __it._M_cur; }
bool operator!=(const iterator& __it) const
{ return _M_cur != __it._M_cur; }
};
可以看出,这里的迭代器设计成只能向后移动,在operator ++ 中,我们可以看到迭代器的移动。
template <class _Val, class _Key, class _HF, class _ExK, class _EqK,
class _All>
_Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>&
_Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>::operator++()
{
const _Node* __old = _M_cur;
_M_cur = _M_cur->_M_next;
if (!_M_cur) {
size_type __bucket = _M_ht->_M_bkt_num(__old->_M_val);
while (!_M_cur && ++__bucket < _M_ht->_M_buckets.size())
_M_cur = _M_ht->_M_buckets[__bucket];
}
return *this;
}
首先在链表(一个bucket)中寻找下一个节点,如果是链表中的最后一个节点,那么寻找下一个链表(bucket)中的节点。了解迭代器之后,开始了解容器本身。
之前可以看出,SGI STL 虽然采用的是开链法,但是在分配空间大小时,依然采用的是质数,这一点和.net framework 中的dictionary一样。大小差不多是2倍
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
//找到下一个大于n的质数,lower_bound是一个二分法查找。
inline unsigned long __stl_next_prime(unsigned long __n)
{
const unsigned long* __first = __stl_prime_list;
const unsigned long* __last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(__first, __last, __n);
return pos == __last ? *(__last - 1) : *pos;
}
hashTable 中最重要的部分是扩容。那么,我们看看,SGI STL是怎么做的
pair<iterator, bool> insert_unique(const value_type& __obj)
{
resize(_M_num_elements + 1);
return insert_unique_noresize(__obj);
}
template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All>
void hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>
::resize(size_type __num_elements_hint)
{
const size_type __old_n = _M_buckets.size();
if (__num_elements_hint > __old_n) {
//如果需要扩容,我们找到下一个质数
const size_type __n = _M_next_size(__num_elements_hint);
if (__n > __old_n) {
//搞一个新的buckets
vector<_Node*, _All> __tmp(__n, (_Node*)(0),
_M_buckets.get_allocator());
__STL_TRY {
for (size_type __bucket = 0; __bucket < __old_n; ++__bucket) {
//遍历之旧的buckets
_Node* __first = _M_buckets[__bucket];
while (__first) {
//遍历旧的bucket,这里,我们根据新的大小找到了新的位置
size_type __new_bucket = _M_bkt_num(__first->_M_val, __n);
//将旧的bucket数据改为 我们正在处理的item的下一个
_M_buckets[__bucket] = __first->_M_next;
//把我们现在处理的item 插入到新的buckets中。
__first->_M_next = __tmp[__new_bucket];
__tmp[__new_bucket] = __first;
//将我们当前处理的item,修改为旧数据的下一个
__first = _M_buckets[__bucket];
}
}
//都搞定了,我们将buckets更换。
_M_buckets.swap(__tmp);
}
#ifdef __STL_USE_EXCEPTIONS
catch(...) {
for (size_type __bucket = 0; __bucket < __tmp.size(); ++__bucket) {
while (__tmp[__bucket]) {
_Node* __next = __tmp[__bucket]->_M_next;
_M_delete_node(__tmp[__bucket]);
__tmp[__bucket] = __next;
}
}
throw;
}
#endif /* __STL_USE_EXCEPTIONS */
}
}
}
当然,这个只是insert_unique ,insert_equal 类似,这里不做描述。
除了resize,hashtable中还有一个吸引我们的就是hash func。但是,一般我们并不会指定hash func, 那么,我们看看SGI STL 是如何选择hash 函数的。
#ifndef __SGI_STL_HASH_FUN_H
#define __SGI_STL_HASH_FUN_H
#include <stddef.h>
__STL_BEGIN_NAMESPACE
template <class _Key> struct hash { };
//字符串这里看来稍微有了一些操作
inline size_t __stl_hash_string(const char* __s)
{
unsigned long __h = 0;
for ( ; *__s; ++__s)
__h = 5*__h + *__s;
return size_t(__h);
}
//这些东西,通过c++ 模板偏特化实现,我们看到,这些东西,啥都没做,只是返回而已。所以,如果
//希望获得最佳的性能,实现仿函数。是非常必要的。
__STL_TEMPLATE_NULL struct hash<char*>
{
size_t operator()(const char* __s) const { return __stl_hash_string(__s); }
};
__STL_TEMPLATE_NULL struct hash<const char*>
{
size_t operator()(const char* __s) const { return __stl_hash_string(__s); }
};
__STL_TEMPLATE_NULL struct hash<char> {
size_t operator()(char __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned char> {
size_t operator()(unsigned char __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<signed char> {
size_t operator()(unsigned char __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<short> {
size_t operator()(short __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned short> {
size_t operator()(unsigned short __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<int> {
size_t operator()(int __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned int> {
size_t operator()(unsigned int __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<long> {
size_t operator()(long __x) const { return __x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned long> {
size_t operator()(unsigned long __x) const { return __x; }
};
SQLite 的hash表。
SQLite是在移动设备上普遍的一个家伙, 他用到了2种HASH, 一种和上面的SGI STL 类似,在PC端,在做增加的时候,判断了数据量大小(一般10个),如果小于,则采用双向链表的方式,不是则采用hash存储。只是,在移动分支中我没有找到,PC端的确有这样的设计,也许在mobile上做了精简。这种hash,用于SQLite底层的内存管理,缓存部分,SQLite采用的是LRU的方式缓存。
另一种Hash是叫做perfect hash。这是一种在最坏情况下,依然能够达到O(1) 的能力,听上去似乎挺吓人的,但是大多数是指固定的表,当然,似乎有些能够做到动态保证,不过,不管他了,我可不是科学家。
SQLite 的前端是需要做词法语法分析的。这部分就涉及到了关键字的保存,这里SQLite 通过perfect hash来达到快速查找。具体的策略了解编译原理的都比较明白,但是,这个的确比较有意思。
构造关键字是通过一个起始位置和长度来获取的。如 “REINDEX 、 INDEXED 、 INDEX 、 DESC”;将保存成“REINDEXEDESC”。那么 REINDEX = (0, 7)。而剩下的工作可以交给一些程序,他们会帮助我们生成perfect hash。
大数据量下,hash信息指纹的应用。可以参考 google黑板报 http://www.google.com.hk/ggblog/googlechinablog/2006/08/blog-post_8115.html